 |
| Clasificación |
Método de Segmentación en Minería de Datos
Cuando se tiene información en una empresa, no es suficiente contar solamente con ella, se requiere analizarla, explorarla y descubrir los patrones que proporcionan la información, por tanto el objetivo es clasificar la información que se desea evaluar y analizar, y así determinar las variables continuas para segmentar o clasificar en grupos y finalmente determinar que ocurre en una base de datos de gran tamaño.
La detección de segmentos sería el objetivo principal de la minería de datos.
La clasificación es un modo de segmentar datos asignándolos a grupos que están previamente definidos. Por tanto, clustering divide la base de datos en diferentes grupos, su objetivo será encontrar grupos que son diferentes entre si.
Las herramientas de minería de datos que normalmente se utilizan para producir estos agrupamientos son: los árboles de decisión y los algoritmos de clustering. La elección de la herramienta dependerá de los objetivos que se persigan con la segmentación.
Técnicas de Segmentación
Las técnicas de la minería de datos provienen de la Inteligencia Artificial y de la estadística, dichas técnicas, no son más que algoritmos, más o menos sofisticados que se aplican sobre un conjunto de datos para obtener unos resultados. Los algoritmos y técnicas más apropiadas para la Segmentación son:
· Técnicas de agrupamiento (clustering)
Es un procedimiento de agrupación de una serie de vectores según criterios habitualmente de distancia; se tratará de disponer los vectores de entrada de forma que estén más cercanos aquellos que tengan características comunes. Ejemplos:
* Algoritmo K-mean.
* Algoritmo K-medoids.
No hay que confundir clustering con segmentación. La segmentación se usa para identificar grupos que tienen características comunes. El clustering es un modo de segmentar datos en grupos que no están previamente definidos.
A diferencia de la clasificación, no se sabe dónde habrá clusters o con que atributos de los datos se harán los clusters.

“El resultado del encadenamiento (clustering) se muestra como el color de los cuadros en 3 grupos (cadenas)"
· Redes Neuronales
Son un paradigma de aprendizaje y procesamiento automático inspirado en la forma en que funciona el sistema nervioso de los animales. Se trata de un sistema de interconexión de neuronas en una red que colabora para producir un estímulo de salida. Algunos ejemplos de red neuronal son:
§ El Perceptrón.
§ El Perceptrón multicapa.
§ Los Mapas Autoorganizados, también conocidos como redes de Kohonen.
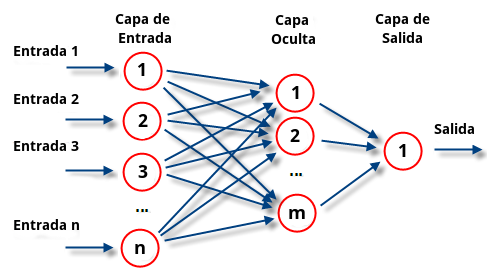
“Red neuronal artificial perceptrón simple con n neuronas de entrada, m neuronas en su capa oculta y una neurona de salida”
· Árboles de decisión
Un árbol de decisión es un modelo de predicción utilizado en el ámbito de la inteligencia artificial, dada una base de datos se construyen estos diagramas de construcciones lógicas, muy similares a los sistemas de predicción basados en reglas, que sirven para representar y categorizar una serie de condiciones que suceden de forma sucesiva, para la resolución de un problema. Ejemplos:
§ Algoritmo ID3.
§ Algoritmo C4.5.
 |
| Ejemplo de Árbol de Decisión |